
All of the images on the home page were generated by DreamBooth.
- Stable Diffusion Explained
- Fine-Tuning Stable Diffusion with Dreambooth
- Training DreamBooth
- Appendix - Stable Diffusion On-Ramp
- General Deep Learning Background
- Transformers and Attention
- Diffusion Models
Stable diffusion is a machine learning model that can generate detailed images based on text descriptions. It is developed by the CompVis group at LMU Munich and released by a collaboration of Stability AI, CompVis LMU, and Runway. The model's code and weights are publicly available, and it can run on most consumer hardware equipped with a GPU. Stable diffusion is used for tasks such as inpainting, outpainting, and generating image-to-image translations guided by a text prompt. It is a latent diffusion model, a type of deep generative neural network.
DreamBooth is a deep learning model that can fine-tune existing text-to-image models. It was developed by researchers from Google Research and Boston University in 2022. DreamBooth can be applied to other text-to-image models, allowing them to generate more personalized and fine-tuned outputs after training on a small number of images of a subject. This makes DreamBooth useful for generating more detailed and accurate images based on text descriptions. It was originally developed using Google's own Imagen text-to-image model.
Stable Diffusion Explained
Stable Diffusion is a deep learning model that uses a technique called latent diffusion to generate detailed images based on text descriptions. This technique is a variant of the diffusion model, which was introduced in 2015.
The Stable Diffusion research paper by Rombach et al.
The process of stable diffusion involves three main components: a variational autoencoder (VAE), a U-Net, and an optional text encoder. The VAE compresses an input image into a lower-dimensional latent space, capturing its fundamental semantic meaning. Gaussian noise is then iteratively applied to this latent representation during forward diffusion.

Stable diffusion process, conditioned on arbitrary text [source: Rombach et al.]
The U-Net block, which is composed of a ResNet backbone, then denoises the output from the forward diffusion process, generating a latent representation of the image. Finally, the VAE decoder converts this representation back into pixel space, generating the final image.
The denoising step in this process can be flexibly conditioned on various types of input data, such as text or images, using a cross-attention mechanism. The model is trained on pairs of images and captions from the LAION-5B dataset, which contains billions of image-text pairs scraped from the web. The trained model can then be used to generate images based on text prompts, or to perform other tasks such as image inpainting or translation.
Fine-Tuning Stable Diffusion with Dreambooth
DreamBooth is a deep learning model that can be used to fine-tune existing text-to-image models, allowing them to generate more personalized and specific outputs. It was developed by researchers at Google Research and Boston University in 2022.
The DreamBooth research paper by Ruiz et al.
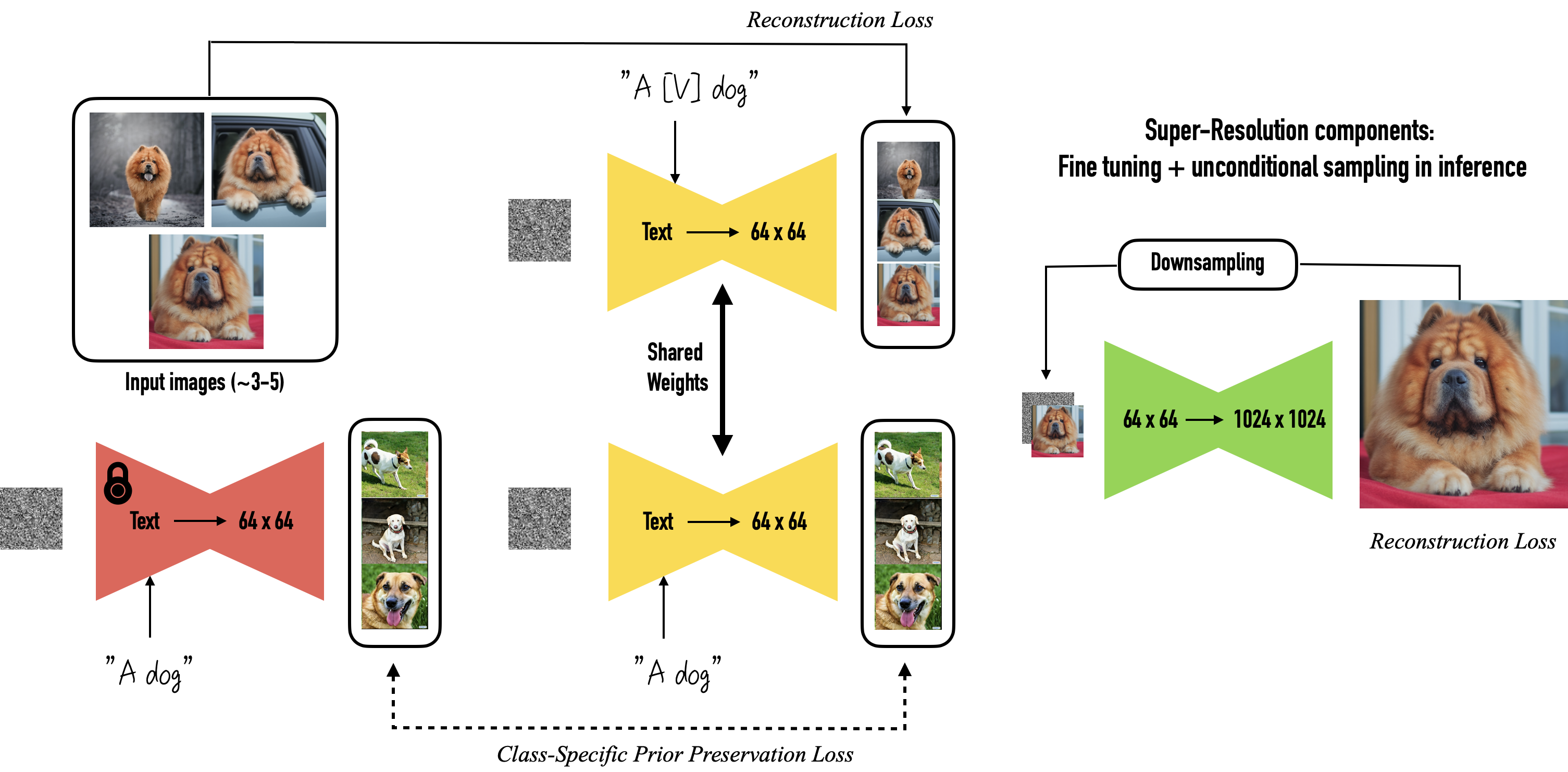
To implement DreamBooth, a small set of images depicting a specific subject is used to fine-tune a pretrained text-to-image model. This usually involves three to five images, paired with text prompts that contain the name of the class the subject belongs to and a unique identifier. For example, if the subject is a person, the text prompt might be "person - Rukmal".
A class-specific prior preservation loss is applied during training, which encourages the model to generate diverse instances of the subject based on what it has already learned about the original class. Pairs of low-resolution and high-resolution images are also used to fine-tune the model's ability to maintain fine details in the generated images.

The fine-tuning process used in DreamBooth [source: Ruiz et al.]
Once fine-tuned, DreamBooth can be used to generate more specific and personalised images based on text prompts. For example, it could be used to generate images of specific individuals, or to render known subjects in different contexts and situations. This can be useful for a variety of applications, but is generally too computationally intensive for hobbyist users to implement.
Training DreamBooth
My implementation of DreamBooth was a fine-tuned version of Stable Diffusion v1-5. It was trained on a p3.8xlarge EC2 instance on AWS. Once the (still hacky) script was done, training took about 20 minutes, with a total of 18 training images. The authors recommended using 3-5 images, but I found that using 20, combined with a lower learning rate yielded better results.
Following recommendations by Ruiz et al., both the diffusion U-Net and the text encoder were fine-tuned with the training images. Additionally, prior-preservation was used to avoid overfitting and language drift in the final model, as recommended by the original authors.
Appendix - Stable Diffusion On-Ramp
This section contains a list of resources that were extremely helpful in building the background knowledge necessary to build DreamBooth.
General Deep Learning Background
- Andrej Karpathy’s series of lectures on Neural Networks, Backpropagation, and LLMs (Neural Networks: Zero to Hero)

- Deep Learning Basics - Introduction and Overview

- Introduction to HuggingFace primitives, NLP models, and using 🤗 Diffusers

Transformers and Attention
- Transfer Learning and Transformer Models (Machine Learning Tech Talk from Google Research)

- Stanford CS224N Lecture 14 - Transformers and Self-Attention

- University of Waterloo CS480/680 Lecture 19: Attention and Transformer Networks

- DETR: End-to-End Object Detection with Transformers Paper Explained by Yannic Kilcher

- Attention is All You Need Paper Explained by Halfling Wizard

Diffusion Models
- Stable Diffusion with 🧨 Diffusers by Patil et al.

- HuggingFace 🧨 Diffusers library explanation notebook

- The Illustrated Stable Diffusion by Jay Alammar

- The Annotated Diffusion Model by Rogge et al.

- What are Diffusion Models? By Lilian Weng
- fast.ai Practical Deep Learning for Coders - Part 2, Lecture 9: Deep Learning Foundations to Stable Diffusion

- Training Stable Diffusion with DreamBooth by Suraj Patil

- Training Stable Diffusion with DreamBooth using 🧨 Diffusers by Patil et al.

{kind=link}